![]()
Verified ARA-R01 dumps Q&As - 2024 Latest ARA-R01 Download
Updated 100% Cover Real ARA-R01 Exam Questions - 100% Pass Guarantee
NEW QUESTION # 81
How does a standard virtual warehouse policy work in Snowflake?
- A. It starts only if the system estimates that there is a query load that will keep the cluster busy for at least 6 minutes.
- B. It conserves credits by keeping running clusters fully loaded rather than starting additional clusters.
- C. It starts only f the system estimates that there is a query load that will keep the cluster busy for at least 2 minutes.
- D. It prevents or minimizes queuing by starting additional clusters instead of conserving credits.
Answer: D
Explanation:
A standard virtual warehouse policy is one of the two scaling policies available for multi-cluster warehouses in Snowflake. The other policy is economic. A standard policy aims to prevent or minimize queuing by starting additional clusters as soon as the current cluster is fully loaded, regardless of the number of queries in the queue. This policy can improve query performance and concurrency, but it may also consume more credits than an economic policy, which tries to conserve credits by keeping the running clusters fully loaded before starting additional clusters. The scaling policy can be set when creating or modifying a warehouse, and it can be changed at any time.
References:
Snowflake Documentation: Multi-cluster Warehouses
Snowflake Documentation: Scaling Policy for Multi-cluster Warehouses
NEW QUESTION # 82 
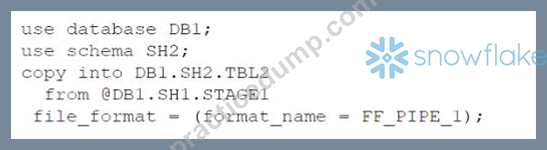
Based on the architecture in the image, how can the data from DB1 be copied into TBL2? (Select TWO).
- A. A white background with black text Description automatically generated

- B. A computer code with black text Description automatically generated
- C. A close-up of a computer code Description automatically generated

- D. A white background with black text Description automatically generated

- E. A close-up of a computer code Description automatically generated

Answer: A,E
Explanation:
The architecture in the image shows a Snowflake data platform with two databases, DB1 and DB2, and two schemas, SH1 and SH2. DB1 contains a table TBL1 and a stage STAGE1. DB2 contains a table TBL2. The image also shows a snippet of code written in SQL language that copies data from STAGE1 to TBL2 using a file format FF PIPE 1.
To copy data from DB1 to TBL2, there are two possible options among the choices given:
Option B: Use a named external stage that references STAGE1. This option requires creating an external stage object in DB2.SH2 that points to the same location as STAGE1 in DB1.SH1. The external stage can be created using the CREATE STAGE command with the URL parameter specifying the location of STAGE11. For example:
SQLAI-generated code. Review and use carefully. More info on FAQ.
use database DB2;
use schema SH2;
createstage EXT_STAGE1
[email protected];
Then, the data can be copied from the external stage to TBL2 using the COPY INTO command with the FROM parameter specifying the external stage name and the FILE FORMAT parameter specifying the file format name2. For example:
SQLAI-generated code. Review and use carefully. More info on FAQ.
copyintoTBL2
from@EXT_STAGE1
file format=(format name=DB1.SH1.FF PIPE1);
Option E: Use a cross-database query to select data from TBL1 and insert into TBL2. This option requires using the INSERT INTO command with the SELECT clause to query data from TBL1 in DB1.SH1 and insert it into TBL2 in DB2.SH2. The query must use the fully-qualified names of the tables, including the database and schema names3. For example:
SQLAI-generated code. Review and use carefully. More info on FAQ.
use database DB2;
use schema SH2;
insertintoTBL2
select*fromDB1.SH1.TBL1;
The other options are not valid because:
Option A: It uses an invalid syntax for the COPY INTO command. The FROM parameter cannot specify a table name, only a stage name or a file location2.
Option C: It uses an invalid syntax for the COPY INTO command. The FILE FORMAT parameter cannot specify a stage name, only a file format name or options2.
Option D: It uses an invalid syntax for the CREATE STAGE command. The URL parameter cannot specify a table name, only a file location1.
References:
1: CREATE STAGE | Snowflake Documentation
2: COPY INTO table | Snowflake Documentation
3: Cross-database Queries | Snowflake Documentation
NEW QUESTION # 83
An Architect needs to design a Snowflake account and database strategy to store and analyze large amounts of structured and semi-structured data. There are many business units and departments within the company. The requirements are scalability, security, and cost efficiency.
What design should be used?
- A. Create a single Snowflake account and database for all data storage and analysis needs, regardless of data volume or complexity.
- B. Use Snowflake's data lake functionality to store and analyze all data in a central location, without the need for structured schemas or indexes
- C. Use a centralized Snowflake database for core business data, and use separate databases for departmental or project-specific data.
- D. Set up separate Snowflake accounts and databases for each department or business unit, to ensure data isolation and security.
Answer: C
Explanation:
The best design to store and analyze large amounts of structured and semi-structured data for different business units and departments is to use a centralized Snowflake database for core business data, and use separate databases for departmental or project-specific data. This design allows for scalability, security, and cost efficiency by leveraging Snowflake's features such as:
Database cloning: Cloning a database creates a zero-copy clone that shares the same data files as the original database, but can be modified independently. This reduces storage costs and enables fast and consistent data replication for different purposes.
Database sharing: Sharing a database allows granting secure and governed access to a subset of data in a database to other Snowflake accounts or consumers. This enables data collaboration and monetization across different business units or external partners.
Warehouse scaling: Scaling a warehouse allows adjusting the size and concurrency of a warehouse to match the performance and cost requirements of different workloads. This enables optimal resource utilization and flexibility for different data analysis needs. References: Snowflake Documentation:
Database Cloning, Snowflake Documentation: Database Sharing, [Snowflake Documentation:
Warehouse Scaling]
NEW QUESTION # 84
Which steps are recommended best practices for prioritizing cluster keys in Snowflake? (Choose two.)
- A. Choose cluster columns that are actively used in the GROUP BY clauses.
- B. Choose columns that are frequently used in join predicates.
- C. Choose TIMESTAMP columns with nanoseconds for the highest number of unique rows.
- D. Choose cluster columns that are most actively used in selective filters.
- E. Choose lower cardinality columns to support clustering keys and cost effectiveness.
Answer: B,D
Explanation:
According to the Snowflake documentation, the best practices for choosing clustering keys are:
Choose columns that are frequently used in join predicates. This can improve the join performance by reducing the number of micro-partitions that need to be scanned and joined.
Choose columns that are most actively used in selective filters. This can improve the scan efficiency by skipping micro-partitions that do not match the filter predicates.
Avoid using low cardinality columns, such as gender or country, as clustering keys. This can result in poor clustering and high maintenance costs.
Avoid using TIMESTAMP columns with nanoseconds, as they tend to have very high cardinality and low correlation with other columns. This can also result in poor clustering and high maintenance costs.
Avoid using columns with duplicate values or NULLs, as they can cause skew in the clustering and reduce the benefits of pruning.
Cluster on multiple columns if the queries use multiple filters or join predicates. This can increase the chances of pruning more micro-partitions and improve the compression ratio.
Clustering is not always useful, especially for small or medium-sized tables, or tables that are not frequently queried or updated. Clustering can incur additional costs for initially clustering the data and maintaining the clustering over time.
References:
Clustering Keys & Clustered Tables | Snowflake Documentation
[Considerations for Choosing Clustering for a Table | Snowflake Documentation]
NEW QUESTION # 85
What step will improve the performance of queries executed against an external table?
- A. Convert the source files' character encoding to UTF-8.
- B. Shorten the names of the source files.
- C. Use an internal stage instead of an external stage to store the source files.
- D. Partition the external table.
Answer: D
Explanation:
Partitioning an external table is a technique that improves the performance of queries executed against the table by reducing the amount of data scanned. Partitioning an external table involves creating one or more partition columns that define how the table is logically divided into subsets of data based on the values in those columns. The partition columns can be derived from the file metadata (such as file name, path, size, or modification time) or from the file content (such as a column value or a JSON attribute). Partitioning an external table allows the query optimizer to prune the files that do not match the query predicates, thus avoiding unnecessary data scanning and processing2 The other options are not effective steps for improving the performance of queries executed against an external table:
Shorten the names of the source files. This option does not have any impact on the query performance, as the file names are not used for query processing. The file names are only used for creating the external table and displaying the query results3 Convert the source files' character encoding to UTF-8. This option does not affect the query performance, as Snowflake supports various character encodings for external table files, such as UTF-8, UTF-16, UTF-32, ISO-8859-1, and Windows-1252. Snowflake automatically detects the character encoding of the files and converts them to UTF-8 internally for query processing4 Use an internal stage instead of an external stage to store the source files. This option is not applicable, as external tables can only reference files stored in external stages, such as Amazon S3, Google Cloud Storage, or Azure Blob Storage. Internal stages are used for loading data into internal tables, not external tables5 References:
1: SnowPro Advanced: Architect | Study Guide
2: Snowflake Documentation | Partitioning External Tables
3: Snowflake Documentation | Creating External Tables
4: Snowflake Documentation | Supported File Formats and Compression for Staged Data Files
5: Snowflake Documentation | Overview of Stages
: SnowPro Advanced: Architect | Study Guide
: Partitioning External Tables
: Creating External Tables
: Supported File Formats and Compression for Staged Data Files
: Overview of Stages
NEW QUESTION # 86
A company wants to Integrate its main enterprise identity provider with federated authentication with Snowflake.
The authentication integration has been configured and roles have been created in Snowflake. However, the users are not automatically appearing in Snowflake when created and their group membership is not reflected in their assigned rotes.
How can the missing functionality be enabled with the LEAST amount of operational overhead?
- A. SCIM must be enabled between the identity provider and Snowflake. Once both are synchronized through SCIM, their groups will get created as group accounts in Snowflake and the proper roles can be granted.
- B. SCIM must be enabled between the identity provider and Snowflake. Once both are synchronized through SCIM. users will automatically get created and their group membership will be reflected as roles In Snowflake.
- C. OAuth must be configured between the identity provider and Snowflake. Then the authorization server must be configured with the right mapping of users, and the resource server must be configured with the right mapping of role assignment.
- D. OAuth must be configured between the identity provider and Snowflake. Then the authorization server must be configured with the right mapping of users and roles.
Answer: B
Explanation:
The best way to integrate an enterprise identity provider with federated authentication and enable automatic user creation and role assignment in Snowflake is to use SCIM (System for Cross-domain Identity Management). SCIM allows Snowflake to synchronize with the identity provider and create users and groups based on the information provided by the identity provider. The groups are mapped to roles in Snowflake, and the users are assigned the roles based on their group membership. This way, the identity provider remains the source of truth for user and group management, and Snowflake automatically reflects the changes without manual intervention. The other options are either incorrect or incomplete, as they involve using OAuth, which is a protocol for authorization, not authentication or user provisioning, and require additional configuration of authorization and resource servers.
NEW QUESTION # 87
A large manufacturing company runs a dozen individual Snowflake accounts across its business divisions. The company wants to increase the level of data sharing to support supply chain optimizations and increase its purchasing leverage with multiple vendors.
The company's Snowflake Architects need to design a solution that would allow the business divisions to decide what to share, while minimizing the level of effort spent on configuration and management. Most of the company divisions use Snowflake accounts in the same cloud deployments with a few exceptions for European-based divisions.
According to Snowflake recommended best practice, how should these requirements be met?
- A. Migrate the European accounts in the global region and manage shares in a connected graph architecture. Deploy a Data Exchange.
- B. Deploy a Private Data Exchange and use replication to allow European data shares in the Exchange.
- C. Deploy a Private Data Exchange in combination with data shares for the European accounts.
- D. Deploy to the Snowflake Marketplace making sure that invoker_share() is used in all secure views.
Answer: C
Explanation:
According to Snowflake recommended best practice, the requirements of the large manufacturing company should be met by deploying a Private Data Exchange in combination with data shares for the European accounts. A Private Data Exchange is a feature of the Snowflake Data Cloud platform that enables secure and governed sharing of data between organizations. It allows Snowflake customers to create their own data hub and invite other parts of their organization or external partners to access and contribute data sets. A Private Data Exchange provides centralized management, granular access control, and data usage metrics for the data shared in the exchange1. A data share is a secure and direct way of sharing data between Snowflake accounts without having to copy or move the data. A data share allows the data provider to grant privileges on selected objects in their account to one or more data consumers in other accounts2. By using a Private Data Exchange in combination with data shares, the company can achieve the following benefits:
The business divisions can decide what data to share and publish it to the Private Data Exchange, where it can be discovered and accessed by other members of the exchange. This reduces the effort and complexity of managing multiple data sharing relationships and configurations.
The company can leverage the existing Snowflake accounts in the same cloud deployments to create the Private Data Exchange and invite the members to join. This minimizes the migration and setup costs and leverages the existing Snowflake features and security.
The company can use data shares to share data with the European accounts that are in different regions or cloud platforms. This allows the company to comply with the regional and regulatory requirements for data sovereignty and privacy, while still enabling data collaboration across the organization.
The company can use the Snowflake Data Cloud platform to perform data analysis and transformation on the shared data, as well as integrate with other data sources and applications. This enables the company to optimize its supply chain and increase its purchasing leverage with multiple vendors.
The other options are incorrect because they do not meet the requirements or follow the best practices. Option A is incorrect because migrating the European accounts to the global region may violate the data sovereignty and privacy regulations, and deploying a Data Exchange may not provide the level of control and management that the company needs. Option C is incorrect because deploying to the Snowflake Marketplace may expose the company's data to unwanted consumers, and using invoker_share() in secure views may not provide the desired level of security and governance. Option D is incorrect because using replication to allow European data shares in the Exchange may incur additional costs and complexity, and may not be necessary if data shares can be used instead. References: Private Data Exchange | Snowflake Documentation, Introduction to Secure Data Sharing | Snowflake Documentation
NEW QUESTION # 88
An Architect is designing a pipeline to stream event data into Snowflake using the Snowflake Kafka connector. The Architect's highest priority is to configure the connector to stream data in the MOST cost-effective manner.
Which of the following is recommended for optimizing the cost associated with the Snowflake Kafka connector?
- A. Utilize a higher Buffer.size.bytes in the connector configuration.
- B. Utilize a lower Buffer.count.records in the connector configuration.
- C. Utilize a higher Buffer.flush.time in the connector configuration.
- D. Utilize a lower Buffer.size.bytes in the connector configuration.
Answer: C
Explanation:
The minimum value supported for the buffer.flush.time property is 1 (in seconds). For higher average data flow rates, we suggest that you decrease the default value for improved latency. If cost is a greater concern than latency, you could increase the buffer flush time. Be careful to flush the Kafka memory buffer before it becomes full to avoid out of memory exceptions.https://docs.snowflake.com/en/user-guide/data-load-snowpipe-streaming-kafka
NEW QUESTION # 89
You are a snowflake architect in an organization. The business team came to to deploy an use case which requires you to load some data which they can visualize through tableau. Everyday new data comes in and the old data is no longer required.
What type of table you will use in this case to optimize cost
- A. TEMPORARY
- B. TRANSIENT
- C. PERMANENT
Answer: B
Explanation:
A transient table is a type of table in Snowflake that does not have a Fail-safe period and can have a Time Travel retention period of either 0 or 1 day. Transient tables are suitable for temporary or intermediate data that can be easily reproduced or replicated1.
A temporary table is a type of table in Snowflake that is automatically dropped when the session ends or the current user logs out. Temporary tables do not incur any storage costs, but they are not visible to other users or sessions2.
A permanent table is a type of table in Snowflake that has a Fail-safe period and a Time Travel retention period of up to 90 days. Permanent tables are suitable for persistent and durable data that needs to be protected from accidental or malicious deletion3.
In this case, the use case requires loading some data that can be visualized through Tableau. The data is updated every day and the old data is no longer required. Therefore, the best type of table to use in this case to optimize cost is a transient table, because it does not incur any Fail-safe costs and it can have a short Time Travel retention period of 0 or 1 day. This way, the data can be loaded and queried by Tableau, and then deleted or overwritten without incurring any unnecessary storage costs.
References: : Transient Tables : Temporary Tables : Understanding & Using Time Travel
NEW QUESTION # 90
An Architect clones a database and all of its objects, including tasks. After the cloning, the tasks stop running.
Why is this occurring?
- A. Cloned tasks are suspended by default and must be manually resumed.
- B. The objects that the tasks reference are not fully qualified.
- C. The Architect has insufficient privileges to alter tasks on the cloned database.
- D. Tasks cannot be cloned.
Answer: A
Explanation:
When a database is cloned, all of its objects, including tasks, are also cloned. However, cloned tasks are suspended by default and must be manually resumed by using the ALTER TASK command. This is to prevent the cloned tasks from running unexpectedly or interfering with the original tasks. Therefore, the reason why the tasks stop running after the cloning is because they are suspended by default (Option C). Options A, B, and D are not correct because tasks can be cloned, the objects that the tasks reference are also cloned and do not need to be fully qualified, and the Architect does not need to alter the tasks on the cloned database, only resume them. References: The answer can be verified from Snowflake's official documentation on cloning and tasks available on their website. Here are some relevant links:
Cloning Objects | Snowflake Documentation
Tasks | Snowflake Documentation
ALTER TASK | Snowflake Documentation
NEW QUESTION # 91
What Snowflake system functions are used to view and or monitor the clustering metadata for a table? (Select TWO).
- A. SYSTEMSCLUSTERING_INFORMATION
- B. SYSTEMSCLUSTERING
- C. SYSTEMSCLUSTERING_DEPTH
- D. SYSTEMSCLUSTERING_RATIO
- E. SYSTEMSTABLE_CLUSTERING
Answer: A,C
Explanation:
The Snowflake system functions used to view and monitor the clustering metadata for a table are:
SYSTEM$CLUSTERING_INFORMATION
SYSTEM$CLUSTERING_DEPTH
Comprehensive But Short Explanation:
TheSYSTEM$CLUSTERING_INFORMATIONfunction in Snowflake returns a variety of clustering information for a specified table. This information includes the average clustering depth, total number of micro-partitions, total constant partition count, average overlaps, average depth, and a partition depth histogram. This function allows you to specify either one or multiple columns for which the clustering information is returned, and it returns this data in JSON format.
TheSYSTEM$CLUSTERING_DEPTHfunction computes the average depth of a table based on specified columns or the clustering key defined for the table. A lower average depth indicates that the table is better clustered with respect to the specified columns. This function also allows specifying columns to calculate the depth, and the values need to be enclosed in single quotes.
References:
SYSTEM$CLUSTERING_INFORMATION: Snowflake Documentation
SYSTEM$CLUSTERING_DEPTH: Snowflake Documentation
NEW QUESTION # 92
An Architect has been asked to clone schema STAGING as it looked one week ago, Tuesday June 1st at 8:00 AM, to recover some objects.
The STAGING schema has 50 days of retention.
The Architect runs the following statement:
CREATE SCHEMA STAGING_CLONE CLONE STAGING at (timestamp => '2021-06-01 08:00:00'); The Architect receives the following error: Time travel data is not available for schema STAGING. The requested time is either beyond the allowed time travel period or before the object creation time.
The Architect then checks the schema history and sees the following:
CREATED_ON|NAME|DROPPED_ON
2021-06-02 23:00:00 | STAGING | NULL
2021-05-01 10:00:00 | STAGING | 2021-06-02 23:00:00
How can cloning the STAGING schema be achieved?
- A. Undrop the STAGING schema and then rerun the CLONE statement.
- B. Modify the statement: CREATE SCHEMA STAGING_CLONE CLONE STAGING at (timestamp =>
'2021-05-01 10:00:00'); - C. Cloning cannot be accomplished because the STAGING schema version was not active during the proposed Time Travel time period.
- D. Rename the STAGING schema and perform an UNDROP to retrieve the previous STAGING schema version, then run the CLONE statement.
Answer: D
Explanation:
The error message indicates that the schema STAGING does not have time travel data available for the requested timestamp, because the current version of the schema was created on 2021-06-02 23:00:00, which is after the timestamp of 2021-06-01 08:00:00. Therefore, the CLONE statement cannot access the historical data of the schema at that point in time.
Option A is incorrect, because undropping the STAGING schema will not restore the previous version of the schema that was active on 2021-06-01 08:00:00. Instead, it will create a new version of the schema with the same name and no data or objects.
Option B is incorrect, because modifying the timestamp to 2021-05-01 10:00:00 will not clone the schema as it looked one week ago, but as it looked when it was first created. This may not reflect the desired state of the schema and its objects.
Option C is correct, because renaming the STAGING schema and performing an UNDROP to retrieve the previous STAGING schema version will restore the schema that was dropped on 2021-06-02
23:00:00. This schema has time travel data available for the requested timestamp of 2021-06-01
08:00:00, and can be cloned using the CLONE statement.
Option D is incorrect, because cloning can be accomplished by using the UNDROP command to access the previous version of the schema that was active during the proposed time travel period.
References: : Cloning Considerations : Understanding & Using Time Travel : CREATE <object> ... CLONE
NEW QUESTION # 93
What are characteristics of the use of transactions in Snowflake? (Select TWO).
- A. The autocommit setting can be changed inside a stored procedure.
- B. A transaction can be started explicitly by executing a begin work statement and end explicitly by executing a commit work statement.
- C. Explicit transactions should contain only DML statements and query statements. All DDL statements implicitly commit active transactions.
- D. Explicit transactions can contain DDL, DML, and query statements.
- E. A transaction can be started explicitly by executing a begin transaction statement and end explicitly by executing an end transaction statement.
Answer: D,E
Explanation:
In Snowflake, a transaction is a sequence of SQL statements that are processed as an atomic unit. All statements in the transaction are either applied (i.e. committed) or undone (i.e. rolled back) together.
Snowflake transactions guarantee ACID properties. A transaction can include both reads and writes1.
Explicit transactions are transactions that are started and ended explicitly by using the BEGIN TRANSACTION, COMMIT, and ROLLBACK statements. Snowflake supports the synonyms BEGIN WORK and BEGIN TRANSACTION, and COMMIT WORK and ROLLBACK WORK. Explicit transactions can contain DDL, DML, and query statements. However, explicit transactions should contain only DML statements and query statements, because DDL statements implicitly commit active transactions. This means that any changes made by the previous statements in the transaction are applied, and any changes made by the subsequent statements in the transaction are not part of the same transaction1.
The other options are not correct because:
B). The autocommit setting can be changed inside a stored procedure, but this does not affect the use of transactions in Snowflake. The autocommit setting determines whether each statement is executed in its own implicit transaction or not. If autocommit is enabled, each statement is committed automatically. If autocommit is disabled, each statement is executed in an implicit transaction until an explicit COMMIT or ROLLBACK is issued. Changing the autocommit setting inside a stored procedure only affects the statements within the stored procedure, and does not affect the statements outside the stored procedure2.
C). A transaction can be started explicitly by executing a BEGIN WORK statement and end explicitly by executing a COMMIT WORK statement, but this is not a characteristic of the use of transactions in Snowflake. This is just one way of writing the statements that start and end an explicit transaction. Snowflake also supports the synonyms BEGIN TRANSACTION and COMMIT, which are recommended over BEGIN WORK and COMMIT WORK1.
D). A transaction can be started explicitly by executing a BEGIN TRANSACTION statement and end explicitly by executing an END TRANSACTION statement, but this is not a valid syntax in Snowflake.
Snowflake does not support the END TRANSACTION statement. The correct way to end an explicit transaction is to use the COMMIT or ROLLBACK statement1.
References:
1: Transactions | Snowflake Documentation
2: AUTOCOMMIT | Snowflake Documentation
NEW QUESTION # 94
How can the Snowpipe REST API be used to keep a log of data load history?
- A. Call insertReport every 8 minutes for a 10-minute time range.
- B. Call loadHistoryScan every minute for the maximum time range.
- C. Call loadHistoryScan every 10 minutes for a 15-minutes range.
- D. Call insertReport every 20 minutes, fetching the last 10,000 entries.
Answer: C
Explanation:
The Snowpipe REST API provides two endpoints for retrieving the data load history: insertReport and loadHistoryScan. The insertReport endpoint returns the status of the files that were submitted to the insertFiles endpoint, while the loadHistoryScan endpoint returns the history of the files that were actually loaded into the table by Snowpipe. To keep a log of data load history, it is recommended to use the loadHistoryScan endpoint, which provides more accurate and complete information about the data ingestion process. The loadHistoryScan endpoint accepts a start time and an end time as parameters, and returns the files that were loaded within that time range. The maximum time range that can be specified is 15 minutes, and the maximum number of files that can be returned is 10,000. Therefore, to keep a log of data load history, the best option is to call the loadHistoryScan endpoint every 10 minutes for a 15-minute time range, and store the results in a log file or a table. This way, the log will capture all the files that were loaded by Snowpipe, and avoid any gaps or overlaps in the time range. The other options are incorrect because:
Calling insertReport every 20 minutes, fetching the last 10,000 entries, will not provide a complete log of data load history, as some files may be missed or duplicated due to the asynchronous nature of Snowpipe. Moreover, insertReport only returns the status of the files that were submitted, not the files that were loaded.
Calling loadHistoryScan every minute for the maximum time range will result in too many API calls and unnecessary overhead, as the same files will be returned multiple times. Moreover, the maximum time range is 15 minutes, not 1 minute.
Calling insertReport every 8 minutes for a 10-minute time range will suffer from the same problems as option A, and also create gaps or overlaps in the time range.
References:
Snowpipe REST API
Option 1: Loading Data Using the Snowpipe REST API
PIPE_USAGE_HISTORY
NEW QUESTION # 95
There are two databases in an account, named fin_db and hr_db which contain payroll and employee data, respectively. Accountants and Analysts in the company require different permissions on the objects in these databases to perform their jobs. Accountants need read-write access to fin_db but only require read-only access to hr_db because the database is maintained by human resources personnel.
An Architect needs to create a read-only role for certain employees working in the human resources department.
Which permission sets must be granted to this role?
- A. USAGE on database hr_db, SELECT on all schemas in database hr_db, SELECT on all tables in database hr_db
- B. MODIFY on database hr_db, USAGE on all schemas in database hr_db, USAGE on all tables in database hr_db
- C. USAGE on database hr_db, USAGE on all schemas in database hr_db, REFERENCES on all tables in database hr_db
- D. USAGE on database hr_db, USAGE on all schemas in database hr_db, SELECT on all tables in database hr_db
Answer: D
Explanation:
To create a read-only role for certain employees working in the human resources department, the role needs to have the following permissions on the hr_db database:
USAGE on the database: This allows the role to access the database and see its schemas and objects.
USAGE on all schemas in the database: This allows the role to access the schemas and see their objects.
SELECT on all tables in the database: This allows the role to query the data in the tables.
Option A is the correct answer because it grants the minimum permissions required for a read-only role on the hr_db database.
Option B is incorrect because SELECT on schemas is not a valid permission. Schemas only support USAGE and CREATE permissions.
Option C is incorrect because MODIFY on the database is not a valid permission. Databases only support USAGE, CREATE, MONITOR, and OWNERSHIP permissions. Moreover, USAGE on tables is not sufficient for querying the data. Tables support SELECT, INSERT, UPDATE, DELETE, TRUNCATE, REFERENCES, and OWNERSHIP permissions.
Option D is incorrect because REFERENCES on tables is not relevant for querying the data.
REFERENCES permission allows the role to create foreign key constraints on the tables.
References:
: https://docs.snowflake.com/en/user-guide/security-access-control-privileges.html#database-privileges
: https://docs.snowflake.com/en/user-guide/security-access-control-privileges.html#schema-privileges
: https://docs.snowflake.com/en/user-guide/security-access-control-privileges.html#table-privileges
NEW QUESTION # 96
What are some of the characteristics of result set caches? (Choose three.)
- A. The retention period can be reset for a maximum of 31 days.
- B. Time Travel queries can be executed against the result set cache.
- C. Each time persisted results for a query are used, a 24-hour retention period is reset.
- D. Snowflake persists the data results for 24 hours.
- E. The result set cache is not shared between warehouses.
- F. The data stored in the result cache will contribute to storage costs.
Answer: A,C,D
Explanation:
Comprehensive and Detailed Explanation: According to the SnowPro Advanced: Architect documents and learning resources, some of the characteristics of result set caches are:
Snowflake persists the data results for 24 hours. This means that the result set cache holds the results of every query executed in the past 24 hours, and can be reused if the same query is submitted again and the underlying data has not changed1.
Each time persisted results for a query are used, a 24-hour retention period is reset. This means that the result set cache extends the lifetime of the results every time they are reused, up to a maximum of 31 days from the date and time that the query was first executed1.
The retention period can be reset for a maximum of 31 days. This means that the result set cache will purge the results after 31 days, regardless of whether they are reused or not. After 31 days, the next time the query is submitted, a new result is generated and persisted1.
The other options are incorrect because they are not characteristics of result set caches. Option A is incorrect because Time Travel queries cannot be executed against the result set cache. Time Travel queries use the AS OF clause to access historical data that is stored in the storage layer, not the result set cache2. Option D is incorrect because the data stored in the result set cache does not contribute to storage costs. The result set cache is maintained by the service layer, and does not incurany additional charges1. Option F is incorrect because the result set cache is shared between warehouses. The result set cache is available across virtual warehouses, so query results returned to one user are available to any other user on the system who executes the same query, provided the underlying data has not changed1. References: Using Persisted Query Results | Snowflake Documentation, Time Travel | Snowflake Documentation
NEW QUESTION # 97
Which security, governance, and data protection features require, at a MINIMUM, the Business Critical edition of Snowflake? (Choose two.)
- A. AWS, Azure, or Google Cloud private connectivity to Snowflake
- B. Extended Time Travel (up to 90 days)
- C. Federated authentication and SSO
- D. Periodic rekeying of encrypted data
- E. Customer-managed encryption keys through Tri-Secret Secure
Answer: A,E
Explanation:
According to the SnowPro Advanced: Architect documents and learning resources, the security, governance, and data protection features that require, at a minimum, the Business Critical edition of Snowflake are:
Customer-managed encryption keys through Tri-Secret Secure. This feature allows customers to manage their own encryption keys for data at rest in Snowflake, using a combination of three secrets: a master key, a service key, and a security password. This provides an additional layer of security and control over the data encryption and decryption process1.
Periodic rekeying of encrypted data. This feature allows customers to periodically rotate the encryption keys for data at rest in Snowflake, using either Snowflake-managed keys or customer-managed keys. This enhances the security and protection of the data by reducing the risk of key compromise or exposure2.
The other options are incorrect because they do not require the Business Critical edition of Snowflake. Option A is incorrect because extended Time Travel (up to 90 days) is available with the Enterprise edition of Snowflake3. Option D is incorrect because AWS, Azure, or Google Cloud private connectivity to Snowflake is available with the Standard edition of Snowflake4. Option E is incorrect because federated authentication and SSO are available with the Standard edition of Snowflake5. References: Tri-Secret Secure | Snowflake Documentation, Periodic Rekeying of Encrypted Data | Snowflake Documentation, Snowflake Editions | Snowflake Documentation, Snowflake Network Policies | Snowflake Documentation, Configuring Federated Authentication and SSO | Snowflake Documentation
NEW QUESTION # 98
Consider the following COPY command which is loading data with CSV format into a Snowflake table from an internal stage through a data transformation query.
This command results in the following error:
SQL compilation error: invalid parameter 'validation_mode'
Assuming the syntax is correct, what is the cause of this error?
- A. The value return_all_errors of the option VALIDATION_MODE is causing a compilation error.
- B. The VALIDATION_MODE parameter does not support COPY statements that transform data during a load.
- C. The VALIDATION_MODE parameter does not support COPY statements with CSV file formats.
- D. The VALIDATION_MODE parameter supports COPY statements that load data from external stages only.
Answer: B
Explanation:
The VALIDATION_MODE parameter is used to specify the behavior of the COPY statement when loading data into a table. It is used to specify whether the COPY statement should return an error if any of the rows in the file are invalid or if it should continue loading the valid rows. The VALIDATION_MODE parameter is only supported for COPY statements that load data from external stages1.
The query in the question uses a data transformation query to load data from an internal stage. A data transformation query is a query that transforms the data during the load process, such as parsing JSON or XML data, applying functions, or joining with other tables2.
According to the documentation, VALIDATION_MODE does not support COPY statements that transform data during a load. If the parameter is specified, the COPY statement returns an error1.
Therefore, option C is the correct answer.
References: : COPY INTO <table> : Transforming Data During a Load
NEW QUESTION # 99
......
Use Real Dumps - 100% Free ARA-R01 Exam Dumps: https://www.practicedump.com/ARA-R01_actualtests.html
Realistic ARA-R01 Dumps Latest Practice Tests Dumps: https://drive.google.com/open?id=1L7rdX67GsKW2UbaxEr9e9EdUXRpCEh9a